Clean Architecture 소개
클린 아키텍쳐에 대해 개발자로써의 관점과 왜 필요한지에 대해 공유합니다.
배경지식
관심사의 분리란? (Separation of Concerns)
관심사의 분리를 설명하기 위해 짧막한 코드 블럭을 작성해봤습니다.
class MyBankAccountView(APIView):
def get(self, request, next_cursor):
currencies = set(request.query_params.getlist('currency'))
Currency.validate(currencies)
u = request.user
q = UserBankAccount.objects.filter(user=u).order_by('-created_at')
if currencies:
q = q.filter(currency__in=currencies)
if next_cursor:
q = q.filter(created_at__lte=next_cursor)
q = q.values(
'currency',
accountNumber=F('account_number'),
# ...
)
return PaginationResponse(q, "Bank accounts have been retrieved")
짧은 코드지만 여러가지 관심사가 들어가 있는 것을 보실 수 있습니다.
- 요청 파라미터 해석
- DB 조회 (ORM)
- 쿼리 생성
- 응답 처리
- Presentation layer 의 응답에 맞춰 Query 를 요청
- Pagination (
PaginationResponse)
물론 간결한 코드로 하나의 API 에 대한 로직을 하나의 함수 안에서 모두 구현 할 수 있어서 지금은 별 문제가 없어 보입니다. 물론 Django ORM 과 Rest Framework 을 잘 활용하면 간결한 코드로 Presentation 레이어 부터 Persistence 레이어까지 구현이 가능합니다.
하지만 Business 요구사항의 변경에 따라 다음과 같은 문제가 생길 수 있습니다.
- UserBankAccount 의 table scheme 가 변경 된다면?
- 아마 여기 뿐만 아니라 여러 군데에서 문제가 생길 것입니다.
- 클라이언트에서 특정 API 에 대해서만 Pagination 처리가 달라진다면?
- 캐싱을 하려면?
- UserBankAccount 를 참조하는 여러 API 가 있는데 이 API 에서만 필요한 Business 로직이 필요하다면?
- 여기서 바로 캐싱 DB 에 접근 하는 로직이 추가 되어야 할 것입니다.
무엇보다 위의 코드에서 가장 큰 문제는 모든 로직이 위의 함수 안에서 구현해야 한다는 것입니다. 1000줄 짜리 함수는 보통 이렇게 시작합니다.
관심사의 분리란 프로그램에서 관심사 별로 쪼개서 각 Component 들이 한 가지 걱정만 함으로써 프로그램 개발과 유지보수 시에 복잡성을 줄이는 것을 의미합니다.
Clean Architecture 에 대해
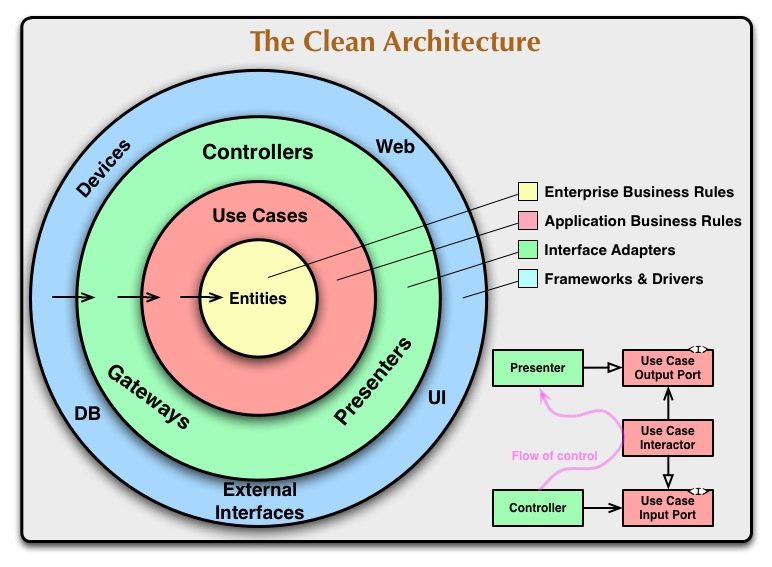
Uncle Bob 이 Clean Architecture 에 대해 기고한 글을 요약해보면 다음과 같습니다.
The Clean Architecture 요약
- 도메인 로직은 프레임워크로 부터 독립해라
아키텍쳐는 프레임워크에 의존하면 안 됩니다. 최소한의 노력으로 새로운 프레임워크를 적용할 수 있어야 합니다. Django 의 Model, Spring 에서 하나의 Entity 를 하나의 DB Table 에 매핑시키는 코드가 Clean Architecture 를 경험해 보셨다면 이러한 모델은 보통 두가지 기능을 동시에 다루게 됩니다.
- 비즈니스 로직을 구현
- Database 에 저장
위 두가지를 동시에 해결하려다보니 코드의 복잡도가 올라간 경험 없으신가요? 예를 들어,
save,load등을 override 해서 DB에 저장하거나 불러올 때 커스터마이즈를 해야만 했던 경험- 하나의 DB Table 로 여러 도메인에 여러 Entity 를 매핑 하는 경우도 자주 있죠.
저장과 비즈니스 로직을 동시에 고려하다보니 머리가 아픈 경험이 많습니다. 1 Entity - 1 Table 구조의 더 큰 문제는 도메인의 Entity 를 설계할 때 DB 에 어떻게 저장할지 고려할 수밖에 없다는 점입니다. 저장은 Domain layer 의 관심사가 아니라 Database layer 의 관심사이기 때문이죠.
- 도메인 로직은 세부 구현으로 부터 독립해라
SW 시스템의 핵심 모듈은 UI, 데이터베이스, 프레임워크, 라이브러리 등의 변경에 영향을 받지 않아야 합니다. 예를 들어 네트워크 라이브러리를 교체 했는데 도메인 로직에 수정이 가해진다면 설계가 제대로 된 것인지 다시 고민해봐야 합니다. 그래서 코드리뷰 할 때 저는 import 영역을 확인하려고 노력합니다.
- 의존성 규칙! 내부 레이어는 상위/외부 레이어의 어떤 것도 알아서는 안된다.
그 결과로 모든 의존성은 안(내부 레이어)를 향해야 합니다. 가장 안에는 도메인 레이어가 존재하죠. 가능한 한 비즈니스 로직을 도메인으로 모으는 훈련이 필요합니다.
- Entity 와 Use case
Entity 와 Use case 가 어플리케이션의 핵심입니다. 아키텍처에 대해서 얘기할 때 이 것들이 존재하는 레이어가 가장 중요합니다. 그리고 이 레이어는 세부구현사항을 담고 있는 레이어(Implementation)의 변경에 영향을 받지 않아야 합니다.
- Adapter 와 Converter 의 필요성
Adapter 와 Converter 는 데이터를 서로 다른 레이어로 전달 할 때 레이어 내부의 세부 사항이 다른 레이어로 전파되지 않도록 하는 역할을 합니다.
즉, 각각의 레이어가 필요로 하는 그들만의 데이터 모델을 외부 레이어로 전달하거나 외부 레이어에서 받아 올 때 외부 또는 내부 레이어의 데이터 모델의 격리를 위해서는 외부 레이어의 데이터 모델을 내부 레이어의 데이어 모델로 변환하는 그리고, 내부 레이어의 데이터 모델을 외부 레이어의 데이터 모델로 변환하는 기능이 필요한데 이 때 Adapter 와 Converter 가 레이어간 완충재 역할을 한다고 보면 되겠습니다. 그리고 이 녀석들을 통해 DDD에서 말하는 Bounded Context 가 좋은 형태로 구현된다고 볼 수 있습니다. 예시를 확인해 보겠습니다.
Adapter 의 예시
- Repository
- Use case 에 주입해주기 위한 interface
- cf. Implemented Repository
Converter 의 예시
- Entity Mapper
- DB 모델을 도메인 모델(Entity) 로 변환
- 의존성 역전의 법칙
이 법칙은 고수준의 모듈이 저수준 모듈에 의존성을 가지면 안된다는 것을 말합니다. SOLID 법칙 에서 마지막 Dependency Inversion Principle 로 소개 되었는데 Depend 양쪽 모듈 모두 추상화에 의존해야 한다는 것이고 추상화 모듈 또한 세부 사항에 의존을 하면 안 된다는 법칙입니다. 즉, 세부 사항이 추상화된 모듈에 의존성을 가져야 합니다.
- 경계(boundary) 간의 데이터 전달
레이어 간 객체를 전달하는 것에는 항상 주의를 기울여야 합니다. 전달되는 객체는 항상 고립되어야 하는데 언어의 기본 형태를 사용해야 하고 감춰진 의존성을 가지면 안 됩니다. ORM (Object Relational Mapping) 라이브러리 사용해봤다면 알 것입니다. 데이터 레이어에 정의된 ORM 객체가 전 레이어를 돌아다닌다는 사실을 말입니다.
Clean architecture 의 장점을 제대로 이해하기 위해서는 소프트웨어 아키텍쳐가 어떻게 진화했는지를 알 필요가 있습니다.
Architecture Evolution
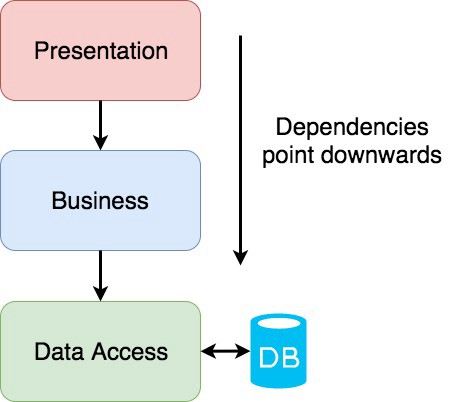
DB 중심 설계
3-Layers Architecture (Eg. MVC)
- Data Layer
비지니스 레이어에서 발생하는 요청을 하부의 데이터 스토리지에 대한 쿼리로 변환하는 걸 담당합니다.
- Business Layer
비지니스 로직과 어플리케이션 로직이 있는 레이어 입니다. 이 레이어는 프리젠테이션 레이어에 독립적이어야 합니다. 하지만 여전히 데이터 레이어에는 명시적인 종속성을 가집니다. 보통 Spring Framework 을 사용하다보면 service 나 controller 에 작성하는 코드로 명시적으로 ORM 을 호출해서 데이터를 가져옵니다.
- Presentation Layer
UI 를 통해 어플리케이션의 기능을 전달하는 걸 담당합니다. 예를 들어 Django 에서의 View 코드가 이에 해당합니다. 이 Layer 는 복잡한 일을 하지 말아야 하고 Versioning 을 담당합니다.
이 Architecture 의 경우 Business layer 와 Data layer 가 강하게 결합하는 경우가 많고 경계가 모호하게 됩니다.
도메인 중심 설계
비즈니스와 환경은 지속적으로 변화하는 것을 가정합니다. 새로운 요구사항에 대해 빠르게 대응할 수 있는 생산성이 중요하다고 생각해서 나온 설계입니다.
왜 도메인 중심 설계를 추구해야할까요?
- 모든 도메인 룰을 한 곳에서 유지하면 모든 레이어가 비지니스 로직을 가지는 부담을 없앨 수 있고, 이로 인해 많은 시간을 절약할 수 있게되고 그 결과 생산성 향상이라는 결과를 만들 수 있기 때문입니다.
DB 중심 설계 → 도메인 중심 설계
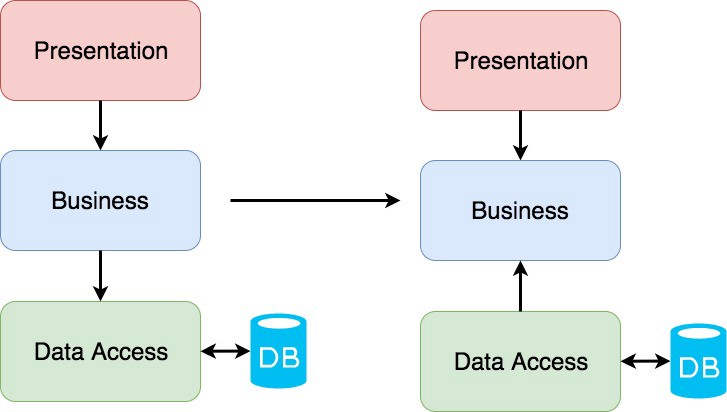
DB 중심 설계와 도메인 중심 설계를 비교하기 위해 간단히 Go 로 구현한 예를 들어 드리겠습니다.
Package 구조
├── entity.go
├── repo
│ ├── db_model.go
│ ├── repo.go
├── repo.go
└── usecase.go
// repo.go - Repository interface definition
type Repository interface {
GetBy(id string) (*Question, error)
Create(Answer) error
GetAnswer(questionID string) (*Answer, error)
SaveAnswer(answer Answer) error
}
// usecase.go - UseCase interface definition
type UseCase interface {
GetBy(id string) (*Question, error)
GetAnswer(questionID string) (*Answer, error)
}
DB 중심 설계
DB 중심의 설계는 도메인 레이어가 DB 레이어에 대해 알고 있습니다. 그러므로 도메인 유스케이스를 생성할 때 리포지토리도 같이 생성합니다.
import "github.com/urunimi/question/repo"
func NewUseCase() UseCase {
return &useCase{repo: repo.NewRepository()}
}
도메인 중심 설계
도메인 중심 설계는 도메인 레이어가 추상화된 리포지토리 인터페이스만 알고 있습니다. 그러므로 도메인 유스케이스를 생성할 때 리포지토리 구현체를 넘겨줘야 합니다. 이렇게 함으로써 도메인 유스케이스는 리포지토리의 구현체에 대해 모르게 할 수 있습니다. 예를 들어 ORM 인터페이스가 리포지토리 인터페이스에는 없고 구현체에 있기 때문에 도메인 로직은 DB 레이어에 대한 로직을 포함할 수 없습니다.
func NewUseCase(repo Repository) UseCase {
return &useCase{repo: repo}
}
댓글남기기